
Continuamos con la publicación de artículos sobre proyectos libres relacionados con la Inteligencia Artificial. En este segundo artículo haremos un repaso a los MoEs (siglas en inglés de Mezcla de Expertos).

¿Qué es una Mezcla de Expertos (MoE)?
La Mezcla de Expertos en la Inteligencia Artificial es una técnica que distribuye tareas específicas entre múltiples submodelos llamados «expertos», cada uno entrenado en un dominio particular de conocimiento.
La clave de esta arquitectura radica en su capacidad para decidir dinámicamente qué experto o combinación de expertos es más adecuado para una tarea determinada, lo que permite una gestión de recursos más eficiente y una mejora en la precisión de las predicciones.
La escala de un modelo es uno de los ejes más importantes para una mejor calidad del modelo. Dado un presupuesto de computación fijo, el entrenamiento de un modelo más grande durante menos pasos es mejor que el entrenamiento de un modelo más pequeño durante más pasos.
La Mezcla de Expertos permite preentrenar modelos con mucho menos cálculo, lo que significa que puedes escalar dramáticamente el tamaño del modelo o del conjunto de datos con el mismo presupuesto de cálculo que un modelo denso. En particular, un modelo MoE debería alcanzar la misma calidad que su homólogo denso mucho más rápido durante el preentrenamiento.
Un MoE consta de dos elementos principales:
– Capas MoE, que tienen un cierto número de «expertos» (normalmente 8), donde cada experto es una red neuronal. Los expertos pueden ser redes más complejas o incluso un MoE en sí mismo.
– Una red de compuertas o enrutador, determina qué tokens se envían a qué experto. Por ejemplo, en la imagen de abajo, el token «More» se envía al segundo experto, y el token «Parameters» se envía a la primera red. Podemos enviar un token a más de un experto.
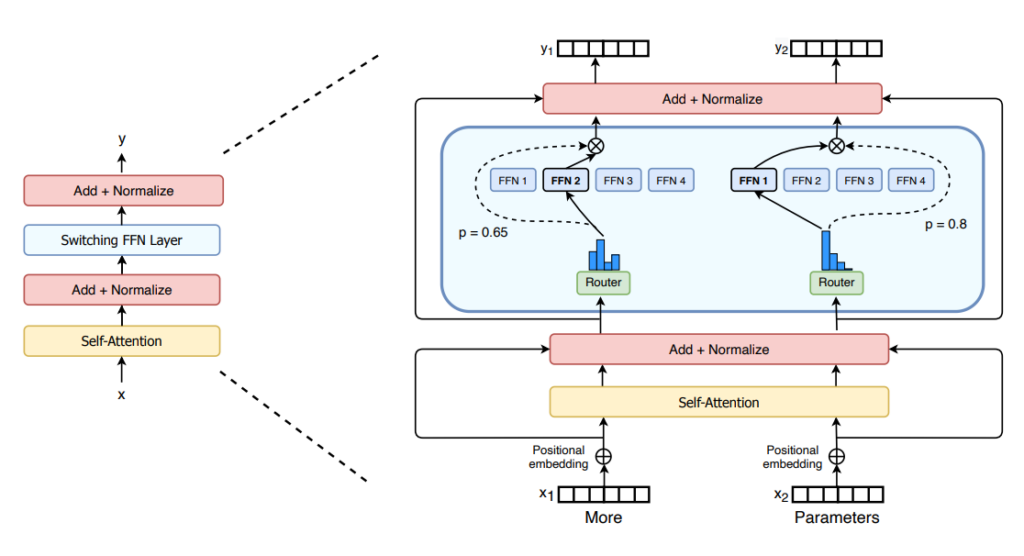
Algunas de las características de los MoEs son:
– Preentrenan mucho más rápido en comparación con los modelos densos
– Tienen una inferencia más rápida en comparación con un modelo con el mismo número de parámetros
– Se requiere alta VRAM ya que todos los expertos están cargados en memoria
– Enfrentan muchos desafíos en el ajuste fino
En resumen, la Mezcla de Expertos en la IA ofrece varias ventajas sobre otros métodos de aprendizaje automático. Es más eficiente, ya que solo necesita ejecutar un experto o una combinación de expertos para cada entrada. Además, es escalable, ya que se puede aumentar el número de expertos para mejorar el rendimiento en problemas complejos. También es versátil, ya que se puede aplicar a una amplia gama de problemas de aprendizaje automático.
Esta arquitectura ha demostrado su eficacia en aplicaciones reales y ofrece numerosas ventajas sobre otros métodos de aprendizaje automático.
Proyectos de código abierto relacionados con los modelos MoE
MoEs de acceso abierto liberados
– Switch Transformers (Google): Colección de MoEs basados en T5, desde 8 hasta 2048 expertos.
– NLLB MoE (Meta): Una variante MoE del modelo de traducción NLLB.
– OpenMoE: Un esfuerzo comunitario que ha liberado MoEs basados en Llama.
– Mixtral 8x7B (Mistral): Un MoE de alta calidad que supera a Llama 2 70B y tiene una inferencia mucho más rápida.
Entrenamiento de los MoE
– Megablocks: https ://github.com/stanford-futuredata/megablocks
– Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
– OpenMoE: https://github.com/XueFuzhao/OpenMoE
Mixtral
Mixtral 8x7b es un gran modelo de lenguaje lanzado por Mistral, que establece un nuevo estado del arte para los modelos de acceso abierto y supera a GPT-3.5 en muchos puntos de referencia.
Mixtral tiene una arquitectura similar a la de Mistral 7B, pero viene con una vuelta de tuerca: realmente son 8 modelos «expertos» en uno solo, gracias a una técnica llamada Mezcla de Expertos (MoE).
Algunas características:
– Versiones base e Instruct
– Soporta una longitud de contexto de 32k tokens
– Supera a Llama 2 70B e iguala o supera a GPT3.5 en la mayoría de los puntos de referencia
– Habla inglés, francés, alemán, español e italiano
– Buena en programación, con 40.2% en HumanEval
– Comercialmente permisiva con una licencia Apache 2.0
Puedes probar a conversar con el modelo Mixtral Instruct en Hugging Face Chat:
https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1