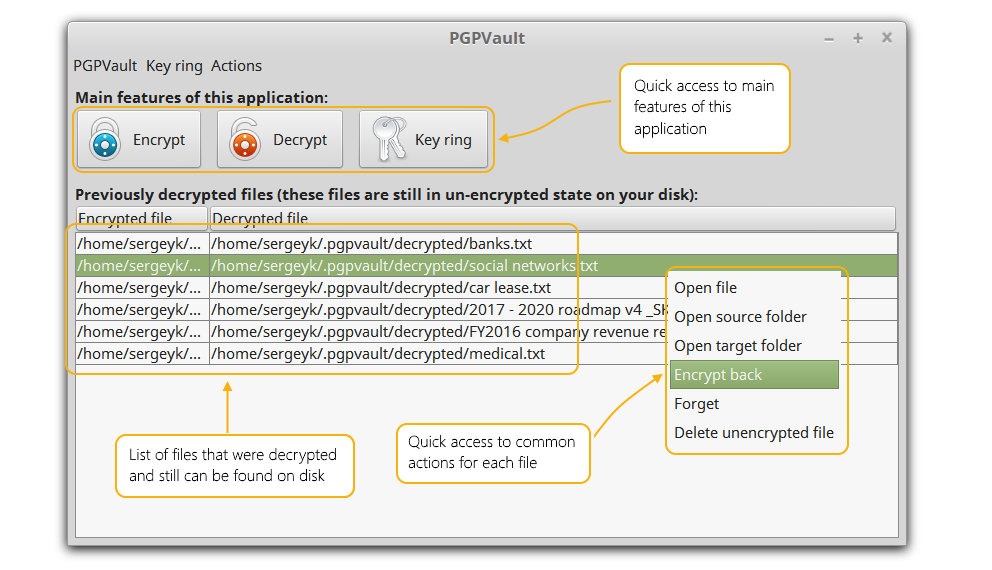
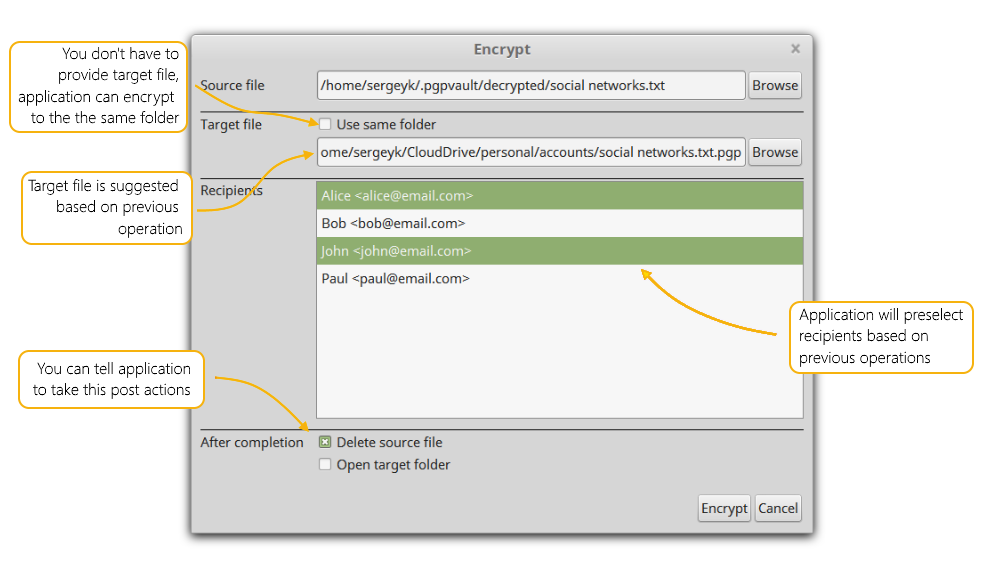
En esta entrega analizamos otra de las herramientas importantes para el trabajo, el cifrado de archivos. PGPTool es una aplicación libre de escritorio con interfaz gráfica (GUI) basada en Java, que facilita el cifrado y descifrado con PGP.
PGP (Pretty Good Privacy) es un sistema de cifrado que se usa para garantizar la seguridad y privacidad de las comunicaciones digitales. Permite cifrar y firmar correos electrónicos, archivos y otros tipos de datos para protegerlos contra accesos no autorizados.
PGP usa un sistema de cifrado de clave pública y privada.
Cada usuario tiene un par de claves: una clave pública, que puede compartir con otras personas, y una clave privada, que debe mantener en secreto.
Para enviar un mensaje cifrado, el remitente usa la clave pública del destinatario. Solo el destinatario puede descifrarlo con su clave privada.
Para firmar digitalmente un mensaje, se usa la clave privada. Así, cualquiera puede verificar la autenticidad del mensaje con la clave pública del remitente.
Usos principales
Seguridad en el correo electrónico: Servicios como ProtonMail o Thunderbird con Enigmail usan PGP para proteger correos.
Autenticación y verificación: Permite comprobar que un mensaje o archivo no ha sido modificado y proviene de una fuente legítima.
Cifrado de archivos: Puede usarse para proteger documentos sensibles.
Variantes y estándares PGP fue desarrollado por Phil Zimmermann en 1991 y evolucionó hasta convertirse en OpenPGP, un estándar abierto adoptado por muchas aplicaciones.
PGPTool
Será especialmente útil para quienes almacenan información sensible en su ordenador y la sincronizan con Google Drive, Dropbox… y no quieren que esta información quede sin cifrar.
Se requiere Java Runtime Environment 1.8 o superior.
Funcionalidades
– Sugiere automáticamente los parámetros de cifrado/descifrado – no es necesario introducirlos manualmente.
– Interfaz gráfica amigable.
– Ayuda a evitar que los datos sensibles queden sin cifrar.
– Compatible con la especificación OpenPGP.
– Soporte multiplataforma – funciona en sistemas GNU/Linux, macOS y Windows.
PGP Tool es al menos un 200 % más fácil de usar que otras herramientas: El cifrado y descifrado no son un fin en sí mismos, sino un medio para alcanzar un objetivo: la seguridad de los datos sensibles.
Existen algunos escenarios comunes:
– Has creado un archivo con información sensible y necesitas almacenarlo o enviarlo por red.
– Has recibido un archivo cifrado y necesitas leer su contenido, actualizarlo y cifrarlo de nuevo antes de enviarlo.
En todos estos casos, también es fundamental asegurarse de que la información sensible no quede en un estado sin cifrar.
Llamafile ofrece una manera sencilla de ejecutar grandes modelos de lenguaje en tu propia máquina. Llamafile es el último proyecto de Mozilla destinado a simplificar la distribución y ejecución de los grandes modelos de lenguaje.
Combina la potencia de llama.cpp, un marco de chatbots LLM de código abierto, con Cosmopolitan Libc, una biblioteca C versátil que asegura compatibilidad entre una amplia variedad de plataformas. Una herramienta que puede transformar los pesos complejos de los modelos en archivos fácilmente ejecutables que funcionan en varios sistemas operativos sin necesidad de instalación.
Llamafile puede tomar un modelo de aprendizaje automático en formato GGUF y convertirlo en un archivo ejecutable en diferentes sistemas operativos.
Mozilla mencionó que:
“Nuestro objetivo es hacer que los modelos de lenguaje grandes de código abierto sean mucho más accesibles tanto para los desarrolladores como para los usuarios finales. Lo estamos logrando combinando llama.cpp con Cosmopolitan Libc en un marco que colapsa toda la complejidad de los LLM en un único archivo ejecutable (llamado «llamafile») que se ejecuta localmente en la mayoría de las computadoras, sin instalación.”
“Supongamos que tienes un conjunto de pesos LLM en forma de archivo de 4 GB (en el formato GGUF de uso común). Con llamafile puedes transformar ese archivo de 4GB en un binario que se ejecuta en seis sistemas operativos sin necesidad de instalación.”
Tienes las instrucciones de instalación y funcionamiento en su GitHub.
Características principales
Multiplataforma: Funciona en macOS, Windows, GNU/Linux, FreeBSD, OpenBSD y NetBSD, compatible con varias arquitecturas de CPU y aceleración por GPU.
Eficiencia y rendimiento: Utiliza tinyBLAS para una aceleración por GPU fluida y optimizaciones recientes para un rendimiento eficiente en CPU, haciendo la IA local más accesible.
Facilidad de uso: Convierte los pesos de los modelos en archivos ejecutables con un solo comando, simplificando el despliegue.
Código abierto e impulsado por la comunidad: Licenciado bajo Apache 2.0, promoviendo las contribuciones de la comunidad y mejoras continuas.
Integración con otras plataformas: Soporta pesos externos, adaptable a diversos casos de uso y compatible con proyectos de IA en plataformas como Hugging Face.
Usabilidad y rendimiento
Para un procesamiento más rápido, puedes usar la GPU de tu ordenador. Esto requiere instalar los controladores apropiados (NVIDIA CUDA para GPUs NVIDIA) y añadir un flag durante la ejecución (consulta la documentación de Llamafile para más detalles).
La experiencia puede variar según el hardware; aquellos que tengan GPUs discretas probablemente verán un mejor rendimiento que los que usen gráficos integrados. Aun así, la capacidad de Llamafile para ejecutar LLMs directamente en tu dispositivo significa que no necesitas depender de caros servicios en la nube. Esto no solo mantiene tus datos privados y seguros, sino que también reduce el tiempo de respuesta, haciendo que las interacciones de IA sean más rápidas y flexibles.
En esta entrega analizaremos otra herramienta importante para el trabajo, la identificación y copia de los textos de las imágenes con TextSnatcher en sistemas GNU/Linux.
TextSnatcher es una aplicación libre y sencilla que nos permite extraer los textos de las imágenes (usando digitalización de textos u OCR). Por detrás trabaja con la potente herramienta libre Tesseract.
Existen muchas herramientas para realizar este trabajo de extracción de textos, pero TextSnatcher facilita mucho el proceso. Permite a los usuarios copiar rápidamente texto de cualquier imagen en la pantalla al portapapeles del sistema.
– La interfaz de la aplicación es muy sencilla de usar. Solo tendremos que utilizar la herramienta de captura de pantalla predeterminada, que nos permitirá seleccionar el tipo de captura de pantalla que deseamos (completa, ventana actual o selección).
– Cuenta con soporte para varios idiomas, que se pueden seleccionar en la interfaz: inglés, tailandés, tamil, japonés, hindi, árabe, ruso, francés, chino (simplificado) y español.
– Utiliza Tesseract OCR 4.x para el reconocimiento de caracteres.
– Está publicada bajo una licencia libre GPL 3.0.
– Puedes acceder al código a través de su repositorio en Github.
Vídeo sobre TextSnatcher
miércoles, 11 diciembre 2024
Proyectos libres de IA – EuroLLM, liderando la IA de Código Abierto en Europa
Continuamos con la publicación de artículos sobre proyectos libres relacionados con la Inteligencia Artificial.
Con el lanzamiento de sus primeros modelos de lenguaje extenso (LLM), el proyecto EuroLLM pretende ofrecer un modelo LLM multilingüe y multimodal competitivo para los 24 idiomas oficiales europeos.
Iniciado en septiembre de 2024 y publicado bajo la licencia de código abierto Apache 2.0, los primeros modelos de EuroLLM ejemplifican cómo la inteligencia artificial (IA) puede adaptarse a la diversidad lingüística de Europa, fomentando al mismo tiempo un ecosistema europeo innovador en IA.
Los primeros modelos de EuroLLM, el EuroLLM-1.7B y su modelo complementario de afinación, EuroLLM-1.7B-Instruct, tienen como objetivo proporcionar a los usuarios europeos un LLM competitivo que pueda recibir indicaciones y generar texto en todos los idiomas oficiales europeos.
Los LLM establecidos suelen centrarse en el inglés y otros pocos idiomas ampliamente hablados. En cambio, EuroLLM propone una solución enfocada a una amplia variedad de lenguas habladas.
Para crear capacidades multilingües y multimodales, EuroLLM entrenó su modelo EuroLLM-1.7B con un amplio conjunto de datos que incluye 4 billones de tokens, representando diferentes fuentes de datos y todos los idiomas considerados. Para la afinación en tareas de instrucción, se desarrolló el modelo EuroLLM-1.7B-Instruct utilizando EuroBlocks, un conjunto de datos multilingües creado por EuroLLM para estas tareas.
El EuroLLM-1.7B-Instruct destacó especialmente al superar el rendimiento de Gemma-2B, el modelo «abierto» de Google basado en la misma investigación que sus modelos Gemini.
Desarrollando LLM disponibles en todos los idiomas oficiales europeos, así como en otros idiomas importantes como el ruso, el árabe y el chino, EuroLLM proporciona a los usuarios europeos y globales acceso a tecnología de IA competitiva en sus idiomas preferidos.
EuroLLM es un proyecto cofinanciado por la Unión Europea y conformado por un consorcio de nueve socios, incluyendo universidades europeas de prestigio, laboratorios técnicos de investigación establecidos y empresas especializadas en traducción con IA, tanto de Europa como de otros lugares. El proyecto también está vinculado a la Empresa Común Europea de Computación de Alto Rendimiento (EuroHPC JU), formando parte de un objetivo estratégico más amplio: crear un ecosistema de IA europeo competitivo e innovador.
Con la publicación de sus modelos bajo una licencia de código abierto, que incluye pesos abiertos, el proyecto tiene el potencial de fomentar la innovación europea en el ámbito de la inteligencia artificial de código abierto.
Presentándose como un proyecto de «código abierto» y «pesos abiertos», los modelos de EuroLLM fueron publicados en HuggingFace tras su lanzamiento. La decisión de abrir los modelos proporciona una base para un desarrollo innovador posterior y demuestra cómo las infraestructuras de supercomputación de la UE pueden ser utilizadas para impulsar la innovación abierta.
Vídeo
miércoles, 13 noviembre 2024
Appointment de Thunderbird, programación de reuniones
Se ha presentado un nuevo proyecto de Thunderbird: Appointment.
Appointment facilita la programación de reuniones con cualquier persona, desde amigos y familiares hasta colegas y desconocidos. Olvídate de los interminables hilos de correos electrónicos intentando encontrar un momento adecuado para reunirte entre diferentes zonas horarias y organizaciones.
Con Appointment, puedes compartir fácilmente tu disponibilidad personalizada y permitir que otros reserven un tiempo en tu agenda. Es simple y directo, sin complicaciones.
Planifica menos, haz más: Appointment de Thunderbird
Si ya has probado herramientas similares, Appointment te resultará familiar, aunque captura lo que hace único a Thunderbird: es software libre y se basa en los valores fundamentales de privacidad, apertura y transparencia.
Appointment formará parte de una suite más amplia de productos útiles que mejoren la experiencia central de Thunderbird.
Appointment se lanzará en diferentes fases, mejorándolo continuamente a medida que abren el acceso a más personas. Actualmente está en beta cerrada, por lo que puedes inscribirte en la lista de espera.
La Open Source Initiative (OSI) se unió a otros colectivos para lanzar el Open Forum for AI (OFAI), con un enfoque centrado en las personas para el desarrollo de la IA. Una iniciativa diseñada por la Universidad Carnegie Mellon (CMU) para promover un enfoque centrado en las personas para la inteligencia artificial.
OFAI tiene como objetivo mejorar nuestra comprensión de la IA y su potencial para aumentar las capacidades humanas, al mismo tiempo que promueve prácticas de desarrollo responsables.
En el centro de OFAI está el compromiso de asegurar que el desarrollo de la IA sirva al interés público. Con el apoyo de socios de renombre como Omidyar Network, NobleReach Foundation y la financiación interna de CMU, OFAI está en posición de ser una plataforma clave para moldear estrategias y políticas de IA que prioricen la seguridad, la privacidad y la equidad.
Stefano Mafulli y Deb Bryant de la OSI participarán en OFAI, integrando sus esfuerzos hacia una definición estándar de IA de Código Abierto a través de un proceso colaborativo que incluya actores de la comunidad de código abierto, la industria y el ámbito académico, así como sus contribuciones a las políticas públicas.
Participantes notables como Michele Jawando de Omidyar Network y Arun Gupta de NobleReach Foundation subrayaron la importancia de la IA de Código Abierto para impulsar la innovación y la inclusión, así como la necesidad de un enfoque centrado en las personas y basado en la confianza para el desarrollo de la IA.
OFAI tiene como objetivo influir en las políticas de IA mediante la coordinación de objetivos de investigación y política, defendiendo un desarrollo de IA transparente e inclusivo.
La iniciativa se centrará en cinco áreas clave:
– Investigación
– Prototipos técnicos
– Recomendaciones políticas
– Compromiso comunitario
– Talento al servicio
Uno de los proyectos fundacionales de OFAI es la creación de un marco de «Apertura en la IA», que busca hacer el desarrollo de la IA más transparente e inclusivo. Este marco servirá como un recurso vital para los responsables políticos, investigadores y la comunidad en general.
Vídeo sobre el Open Forum for AI
jueves, 12 septiembre 2024
Aplicaciones libres orientadas a empresa – gestión de proyectos con OpenProject
En esta entrega analizaremos otra herramienta fundamental para el trabajo, el gestor de proyectos OpenProject.
OpenProject es una solución completa de software libre para la gestión de proyectos. Una potente herramienta de código abierto que ofrece una amplia gama de funcionalidades para cubrir las necesidades de equipos y organizaciones de todos los tamaños. La plataforma permite a los usuarios aplicar metodologías de gestión de proyectos clásicas, ágiles o híbridas en un entorno seguro y colaborativo.
Planificación y programación
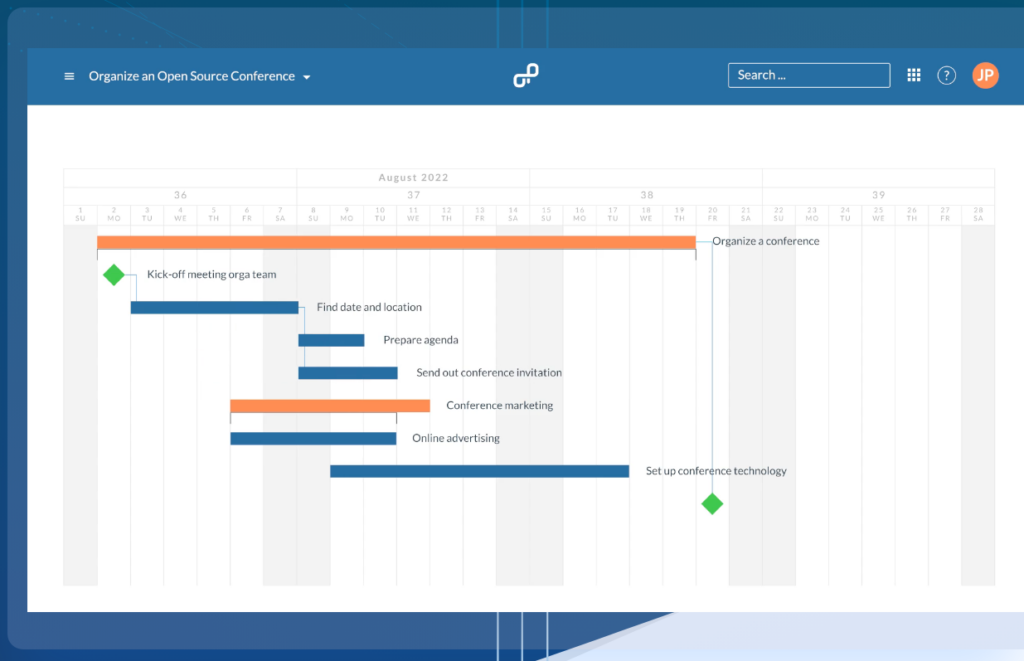
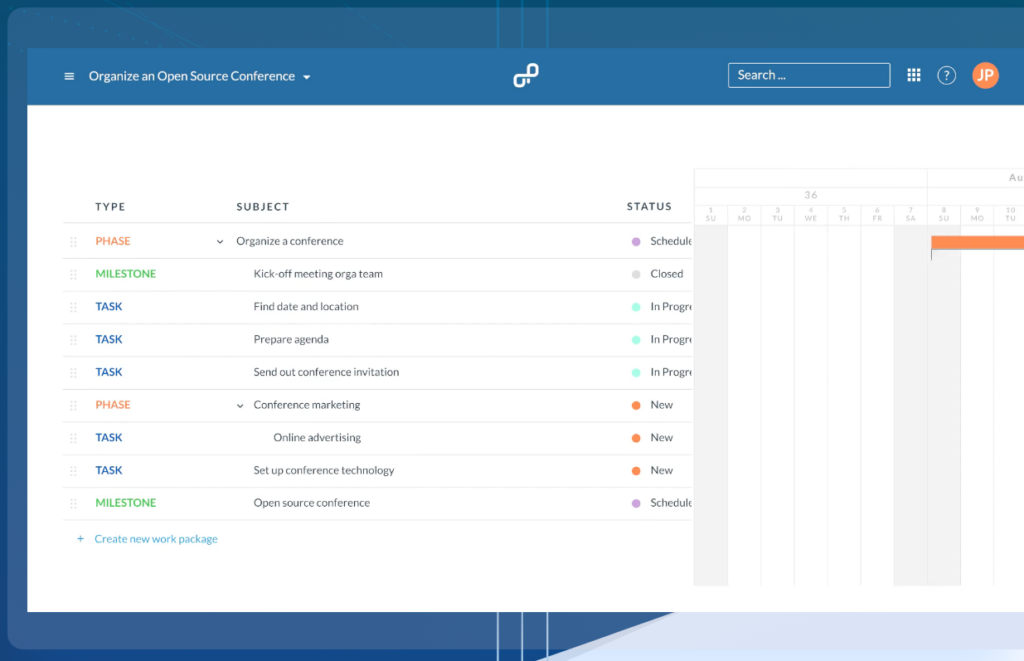
OpenProject proporciona herramientas robustas para la planificación y programación de proyectos. Los usuarios pueden crear y visualizar planes de proyecto usando diagramas de Gantt, lo que facilita descomponer actividades y establecer calendarios detallados para alcanzar los objetivos del proyecto de manera eficiente.
Metodologías ágiles
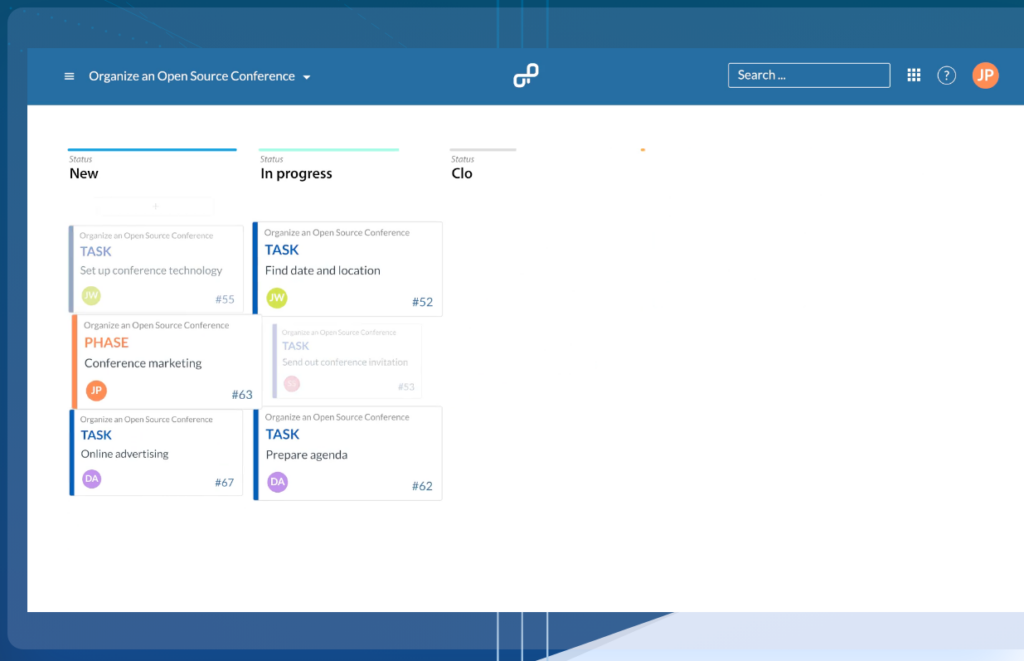
La plataforma es compatible con metodologías ágiles como Scrum y Kanban. Los tableros ágiles de OpenProject permiten organizar al equipo de forma eficaz y tener una visión clara del progreso del proyecto, favoreciendo la colaboración y la adaptación.
Planificación de recursos
El planificador de equipos de OpenProject permite asignar tareas visualmente a los miembros del equipo en un calendario semanal o quincenal. Esta función ayuda a gestionar la carga de trabajo y proporciona una mejor perspectiva de las actividades en curso.
Seguridad y protección de datos
OpenProject da gran importancia a la seguridad y protección de los datos:
– La plataforma se puede instalar en la infraestructura propia de la organización, ofreciendo control total sobre los datos.
– Incluye cifrado HTTPS, contraseñas seguras, autenticación de dos factores y definición del tiempo de sesión.
– Al ser de código abierto, permite una visión clara del código fuente y la libertad de usar, distribuir, estudiar y modificar el software sin restricciones.
Opciones de implementación
OpenProject ofrece diferentes opciones para adaptarse a las necesidades específicas de cada organización:
– Community Edition: Versión gratuita con una amplia variedad de funciones básicas.
– Enterprise On-Premises: Incluye soporte profesional, extensiones empresariales y funcionalidades de seguridad adicionales para instalaciones autoalojadas.
– Enterprise Cloud: Solución SaaS alojada por OpenProject, que incluye soporte profesional y extensiones empresariales sin necesidad de configuración técnica.
Casos de uso
OpenProject ha demostrado ser beneficioso para diversas organizaciones:
– Varias universidades lo utilizan para que los estudiantes apliquen técnicas de gestión de proyectos en la práctica.
– En las empresas facilita la planificación rápida y exhaustiva de proyectos, mejorando la coordinación con clientes.
– En la Administración pública ayuda a visualizar cronogramas y mejorar la coordinación entre los miembros del equipo.
– En las organizaciones sin ánimo de lucro proporciona una plataforma centralizada para organizar tareas y mejorar la eficiencia en la gestión de proyectos.
Vídeo sobre el gestor de proyectos
miércoles, 14 agosto 2024
Proyectos libres de IA – Mejorando la accesibilidad con IA
Continuamos con la publicación de artículos sobre proyectos libres relacionados con la Inteligencia Artificial.
Después de llevar el sistema Braille al mundo digital y crear el primer lector de pantalla para la web, la Dra. Asakawa está trabajando en un dispositivo con inteligencia artificial para ayudar a las personas ciegas a navegar por el mundo de forma independiente, un sistema de navegación interior llamado Maleta IA:
«Cuando comencé en IBM en 1985, me di cuenta de que la tecnología tiene el poder de cambiar y mejorar nuestra calidad de vida, especialmente para aquellas personas que están marginadas por la sociedad,» dice la Dra. Chieko Asakawa, miembro de IBM y directora ejecutiva del Museo Nacional de Ciencia e Innovación Emergente (Miraikan).
«Me di cuenta de que nosotros, es decir, científicos, investigadores, ingenieros, y otros, podíamos hacer lo imposible posible. Estaba emocionada por las posibilidades.»
Desde entonces, la Dra. Asakawa ha hecho precisamente eso, desarrollando tecnologías que permiten a las personas con discapacidades visuales interactuar con el mundo que las rodea y participar en él de maneras que anteriormente eran difíciles o imposibles.
Algunos de sus primeros proyectos en IBM consistieron en digitalizar el sistema Braille, el sistema de lectura y escritura basado en el tacto en el que los puntos en relieve corresponden al lenguaje, creando un procesador de texto y una biblioteca digital para Braille. En los años 90, con el surgimiento de la web, la Dra. Asakawa vio otra oportunidad y creó el Home Page Reader, el primer lector de pantalla que daba acceso a Internet a las personas ciegas.
A medida que la tecnología avanzó, también lo hicieron las aspiraciones de la Dra. Asakawa, y recientemente ha trabajado en el uso de la tecnología para ayudar con barreras de accesibilidad mucho más complejas: el mundo en general. Parte de construir estas tecnologías, explica ella, es la capacidad de colaborar con otros. Por ejemplo, el feedback que recibió de los usuarios del Home Page Reader ayudó a definir la interfaz de navegación, que utilizaba un teclado numérico en lugar de un ratón, y distinguía los enlaces del texto normal leyéndolos con una voz diferente.
El software libre está permitiendo más colaboración que nunca. Las licencias abiertas permiten que las personas construyan sobre el código de los demás y desbloqueen muchos de los problemas de propiedad intelectual que podrían impedir la colaboración a través de los límites organizativos.
CaBot y otros proyectos
El equipo de la Dra. Chieko Asakawa ha estado trabajando en un proyecto de código abierto llamado CaBot (Carry On Robot), una maleta habilitada con IA diseñada para ayudar a navegar por aeropuertos y otros espacios, que atrajo contribuyentes de todo el mundo.
CaBot es solo uno de varios proyectos en los que la Dra. Asakawa ha estado trabajando en los últimos años. Como parte del Laboratorio de Asistencia Cognitiva de Carnegie Mellon (CAL), exploró varias formas en que la IA puede ser utilizada para «comprender el mundo circundante para dar sentido a la información para las personas que no pueden ver.»
El grupo también creó una aplicación para smartphones que ayuda a reconocer objetos personales y otra para ayudar con la navegación interior, ambas parte del proyecto de código abierto Human-scale Localization Platform (HULOP). Un tema común entre los proyectos de la Dra. Asakawa es proporcionar autonomía e independencia con la ayuda de la tecnología. Habló de este tema durante su charla TED en 2015.
Vídeo sobre la accesibilidad con IA
miércoles, 10 julio 2024
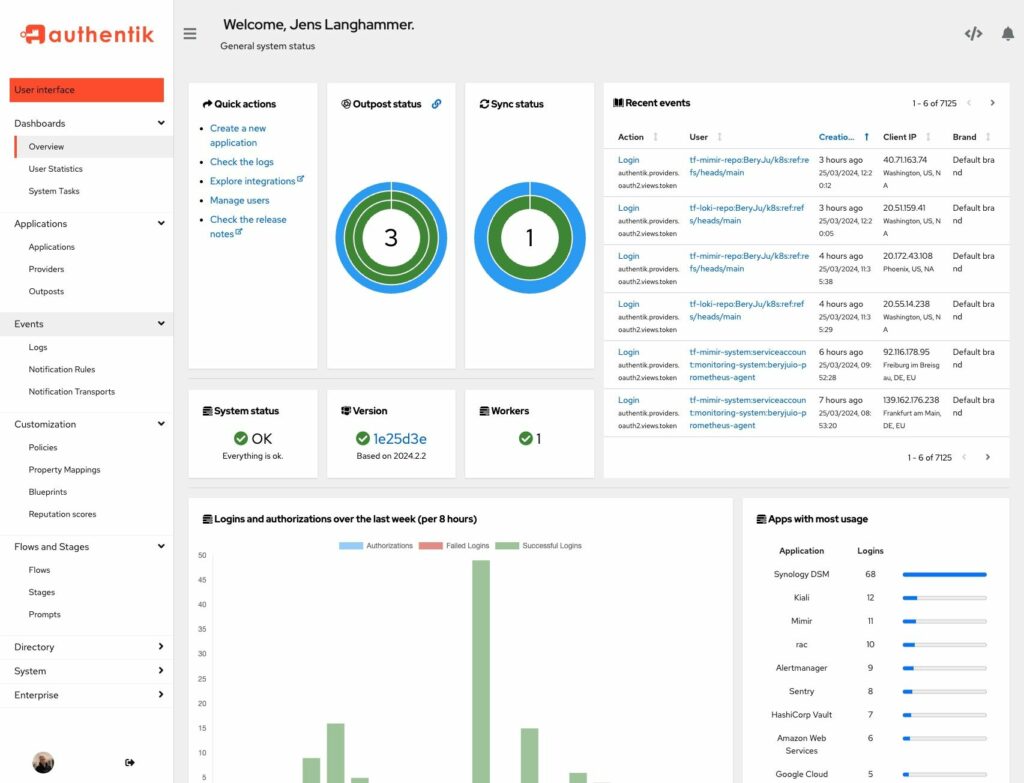
Aplicaciones libres orientadas a empresa – authentik, proveedor de identidad autogestionado
En esta entrega analizaremos una herramienta para tomar el control de tus datos más sensibles en la empresa.
authentik es un proveedor de identidad de software libre que enfatiza la flexibilidad y la versatilidad. Se puede integrar sin problemas en entornos existentes para soportar nuevos protocolos.
authentik también es una solución para implementar registro, recuperación y otras características similares en tu aplicación, ahorrándote el trabajo de gestionarlas.
A medida que internet y los servicios se convierten cada vez más en la norma en nuestra sociedad, proteger nuestros servicios con autenticación también se ha vuelto más importante. Aquí es donde entran proyectos como authentik. Esta solución te ofrece la oportunidad de configurar un sistema de inicio de sesión único para todos tus servicios. Esto significa que solo necesitas tener un inicio de sesión muy seguro y puedes acceder a cualquiera de los servicios que utilizas todos los días.
Con authentik, ya no necesitas confiar continuamente en un servicio de terceros.
Características de authentik
– Posee tus datos. No necesitas depender de un servicio de terceros para la infraestructura crítica ni exponer tus datos sensibles a internet pública.
– Flexible y escalable. Utiliza los flujos de trabajo preconstruidos, o personaliza cada paso de la autenticación mediante modelos configurables, infraestructura como código y APIs completas.
– Seguridad a través de la transparencia. El código abierto es continuamente revisado por expertos en la comunidad, y priorizamos la seguridad desde el diseño hasta el código, pruebas y mantenimiento.
– Precios simplificados. No más adivinar si una característica está incluida o pagar extra por funcionalidades básicas. Cubre tanto los casos de uso B2B como B2C.
– Automatiza y simplifica. Adopta authentik a tu entorno, independientemente de tus requisitos. Usa las APIs y políticas totalmente personalizables para automatizar cualquier flujo de trabajo. Simplifica el despliegue y la escalabilidad con modelos preconstruidos y soporte para Kubernetes, Terraform y Docker Compose.
– Despliegue. CoreWeave colabora con grandes empresas de IA para desplegar authentik como una herramienta esencial de autenticación.
Vídeo sobre authentik
miércoles, 12 junio 2024
Proyectos libres de IA – Open Medical-LLM Leaderboard
Continuamos con la publicación de artículos sobre proyectos libres relacionados con la Inteligencia Artificial. En este artículo haremos un repaso del Open Medical-LLM Leaderboard.
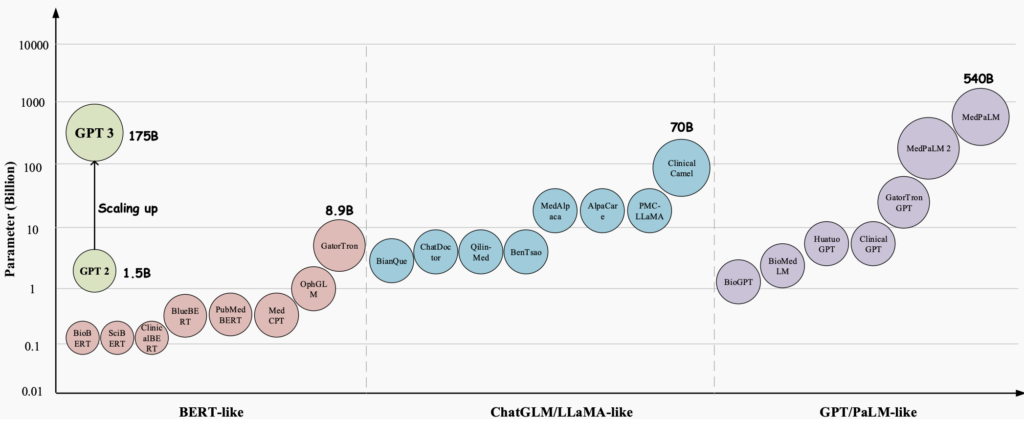
A lo largo de los años, los Modelos de Lenguaje Grande (LLMs) han emergido como una tecnología revolucionaria con un potencial inmenso para transformar diversos aspectos de la salud. Estos modelos, como GPT-3, GPT-4 y Med-PaLM 2, han demostrado capacidades notables en la comprensión y generación de texto similar al humano, convirtiéndose en herramientas valiosas para afrontar tareas médicas complejas y mejorar la atención al paciente. Han mostrado un gran potencial en varias aplicaciones médicas, como preguntas y respuestas médicas (QA), sistemas de diálogo y generación de texto.
Además, con el crecimiento exponencial de los registros electrónicos de salud (EHRs), la literatura médica y los datos generados por los pacientes, los LLMs podrían ayudar a los profesionales de la salud a extraer información valiosa y tomar decisiones informadas.
Sin embargo, a pesar del inmenso potencial de los Modelos de Lenguaje Grande (LLMs) en la salud, hay retos significativos y específicos que necesitan ser abordados.
Cuando los modelos se usan para aspectos conversacionales recreativos, los errores tienen pocas repercusiones; esto no es el caso para usos en el ámbito médico, donde una explicación o respuesta incorrecta puede tener consecuencias graves para el cuidado y los resultados del paciente. La precisión y la fiabilidad de la información proporcionada por los modelos de lenguaje pueden ser una cuestión de vida o muerte, ya que podrían afectar potencialmente las decisiones de salud, el diagnóstico y los planes de tratamiento.
Para aprovechar plenamente el poder de los LLMs en la atención sanitaria, es crucial desarrollar y comparar modelos utilizando un conjunto específico diseñado para el dominio médico. Este conjunto debe tener en cuenta las características y requisitos únicos de los datos y aplicaciones sanitarias. El desarrollo de métodos para evaluar el Medical-LLM no es sólo de interés académico sino también de importancia práctica, dados los riesgos reales que suponen en el sector sanitario.
Open Medical-LLM Leaderboard
El Tablero de Clasificación Open Medical-LLM tiene como objetivo rastrear, clasificar y evaluar el rendimiento de los grandes modelos de lenguaje (LLMs) en tareas de respuesta a preguntas médicas.
Evalúa los LLMs a través de una amplia variedad de conjuntos de datos médicos, incluyendo MedQA (USMLE), PubMedQA, MedMCQA y subconjuntos de MMLU relacionados con la medicina y la biología. El tablero ofrece una evaluación comprensiva del conocimiento médico y de las capacidades de respuesta a preguntas de cada modelo.
Los conjuntos de datos cubren varios aspectos de la medicina, como el conocimiento médico general, el conocimiento clínico, la anatomía, la genética y más. Contiene preguntas de opción múltiple y preguntas abiertas que requieren razonamiento y comprensión médica.
Al ofrecer una evaluación comprensiva del conocimiento médico y de las capacidades de respuesta a preguntas de cada modelo, el tablero pretende fomentar el desarrollo de LLMs médicos más efectivos y fiables.
Esta plataforma permite a los investigadores y profesionales identificar las fortalezas y debilidades de diferentes enfoques, impulsar nuevos avances en el campo y, en última instancia, contribuir a una mejor atención y resultados para los pacientes.
Conjuntos de Datos, Tareas y Configuración de Evaluación
MedQA
El conjunto de datos MedQA consiste en preguntas de opción múltiple del Examen de Licencia Médica de los Estados Unidos (USMLE). Cubre conocimientos médicos generales e incluye 11,450 preguntas en el conjunto de desarrollo y 1,273 preguntas en el conjunto de pruebas. Cada pregunta tiene 4 o 5 opciones de respuesta, y el conjunto de datos está diseñado para evaluar los conocimientos médicos y las habilidades de razonamiento necesarias para la licencia médica en los Estados Unidos.
MedMCQA
MedMCQA es un conjunto de datos de QA de opción múltiple a gran escala derivado de los exámenes de ingreso médico indios (AIIMS/NEET). Cubre 2.4k temas de salud y 21 materias médicas, con más de 187,000 preguntas en el conjunto de desarrollo y 6,100 preguntas en el conjunto de pruebas. Cada pregunta tiene 4 opciones de respuesta y va acompañada de una explicación. MedMCQA evalúa los conocimientos médicos generales y las capacidades de razonamiento de un modelo.
PubMedQA
PubMedQA es un conjunto de datos de QA de dominio cerrado, en el que cada pregunta puede ser respondida mirando un contexto asociado (resumen de PubMed). Consta de 1,000 pares de preguntas-respuestas etiquetadas por expertos. Cada pregunta va acompañada de un resumen de PubMed como contexto, y la tarea es proporcionar una respuesta sí/no/tal vez basada en la información en el resumen. El conjunto de datos se divide en 500 preguntas para desarrollo y 500 para pruebas. PubMedQA evalúa la capacidad de un modelo para comprender y razonar sobre literatura biomédica científica.
Subconjuntos de MMLU (Medicina y Biología)
El benchmark MMLU (Medición de Comprensión Multitarea Masiva) incluye preguntas de opción múltiple de varios dominios. Para el Tablero de Clasificación Abierto de Medical-LLM, nos centramos en los subconjuntos más relevantes para el conocimiento médico:
Conclusiones
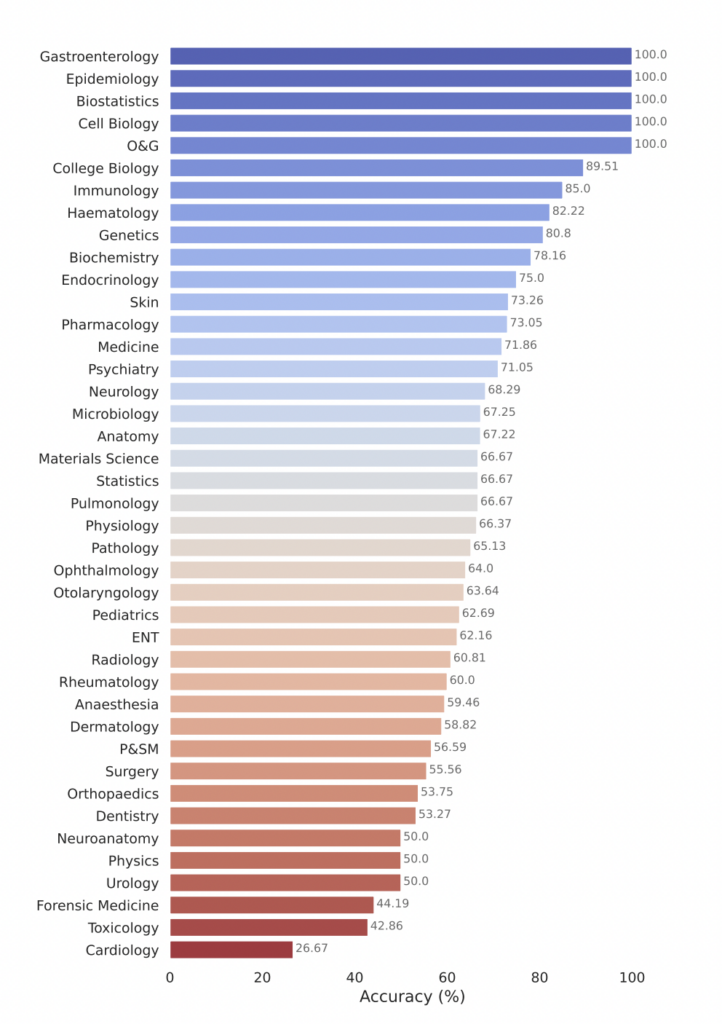
El Open Medical-LLM Leaderboard evalúa el rendimiento de varios modelos de lenguaje grande (LLMs) en un conjunto diverso de tareas de preguntas y respuestas médicas. Principales conclusiones:
– Modelos comerciales como GPT-4-base y Med-PaLM-2 alcanzan consistentemente altas puntuaciones de precisión en varios conjuntos de datos médicos, demostrando un fuerte rendimiento en diferentes dominios médicos.
– Los modelos de código abierto, como Starling-LM-7B, gemma-7b, Mistral-7B-v0.1 y Hermes-2-Pro-Mistral-7B, muestran un rendimiento competitivo en ciertos conjuntos de datos y tareas, a pesar de tener tamaños más pequeños de alrededor de 7 mil millones de parámetros.
– Tanto los modelos comerciales como los de código abierto tienen un buen rendimiento en tareas como la comprensión y el razonamiento sobre literatura biomédica científica (PubMedQA) y la aplicación de conocimientos clínicos y habilidades de toma de decisiones (subconjunto de conocimientos clínicos de MMLU).
El modelo de Google, Gemini Pro, demuestra un fuerte rendimiento en varios dominios médicos, destacando especialmente en tareas intensivas en datos y procedimientos como Bioestadística, Biología Celular y Obstetricia y Ginecología. No obstante, muestra un rendimiento moderado a bajo en áreas críticas como Anatomía, Cardiología y Dermatología, revelando lagunas que requieren un mayor refinamiento para una aplicación médica integral.
Open Life Science AI
Open Life Science AI es un proyecto que tiene como objetivo revolucionar la aplicación de la inteligencia artificial en los ámbitos de las ciencias de la vida y la salud.
Sirve como un punto central para una lista de modelos médicos, conjuntos de datos, referencias y seguimiento de fechas límite de conferencias, fomentando la colaboración, la innovación y el progreso en el campo de la salud asistida por IA.
Nos esforzamos por establecer Open Life Science AI como el destino principal para cualquier interesado en la intersección entre la IA y la salud. Proporcionamos una plataforma para que investigadores, clínicos, formuladores de políticas y expertos de la industria puedan participar en diálogos, compartir conocimientos y explorar los últimos avances en el campo.
En esta entrega analizaremos una herramienta muy útil en el trabajo, como es la gestión de los tiempos y pausas en nuestras actividades.
La aplicación Pomatez es una herramienta de gestión del tiempo basada en la técnica Pomodoro, diseñada para mejorar la productividad. Esta aplicación, se enfoca en dividir el trabajo en intervalos de tiempo cortos y concentrados, seguidos de breves descansos.
Método Pomodoro
El método Pomodoro es una técnica de gestión del tiempo creada en los años 80. Su idea principal es dividir el trabajo en períodos cortos de tiempo, generalmente de 25 minutos, llamados «Pomodoros», seguidos de un breve descanso de 5 minutos. Después de cuatro Pomodoros, se hace un descanso más largo de 15-30 minutos.
El objetivo de este método es ayudar a la persona a concentrarse más intensamente en la tarea durante el tiempo asignado y evitar la fatiga mental. Al dividir el trabajo en bloques pequeños, es más fácil mantener la concentración y evitar la procrastinación. Además, el método Pomodoro promueve la idea de registrar las tareas y el tiempo empleado en cada una, lo que puede ayudar a analizar la propia productividad e identificar áreas de mejora.
Pomatez
Algunos aspectos clave de Pomatez incluyen reglas personalizables, una lista de tareas integrada, notificaciones de escritorio, pausas especiales, accesos directos de teclado, actualizaciones automáticas, asistencia por voz y modo oscuro, entre otras.
Pomatez es una herramienta útil para aquellos que buscan optimizar su tiempo y mejorar su productividad en diversas actividades, desde el estudio hasta el trabajo.
– Lista de tareas incorporada: te permite crear una simple lista de tareas pendientes y marcar las tareas hechas cuando están completadas.
– Pausas a pantalla completa: una vez habilitadas, te obliga a no continuar trabajando durante el tiempo de pausa ocupando toda la pantalla de tu escritorio.
– Notificaciones de escritorio: los tipos de notificaciones admitidas son:
Ninguna – no se mostrará ninguna notificación. Predeterminado.
Normal – mostrará notificación en cada pausa.
Extra – mostrará notificación 60 segundos antes de que comience la pausa, y 30 segundos antes de que la pausa termine, y cuando la pausa realmente comience.
Pausas especiales – una característica especial que permite establecer momentos específicos para hacer pausas importantes como almuerzo, merienda, cena y etc., sin actualizar la configuración del Pomodoro.
– Asistencia vocal: una vez habilitada, tu notificación de escritorio incluirá una voz masculina para informarte sobre cosas relacionadas con tu sesión de Pomodoro. A veces útil especialmente cuando estás lejos de tu ordenador durante el tiempo de pausa.
– Tema oscuro: te permite usar el modo oscuro y ayudarte a reducir la tensión ocular y mejorar la visibilidad si eres del tipo de persona con baja visión y alta sensibilidad a la luz brillante.
PDF (Portable Document Format) es un formato de archivo abierto creado por Adobe para crear documentos impresos como si se tratase de una imagen electrónica que el usuario puede observar en el PC, imprimir… empleando un programa lector apropiado. El aspecto de los documentos es independiente del dispositivo electrónico en el que se visualice.
Se emplea cuando se quiere conservar un documento con una apariencia determinada y no se pretende que se vaya a editar. De todas formas, en algún momento será necesario hacer algún tipo de edición, por lo que existen varios programas para poder editar pdf’s que permiten unir/dividir/eliminar páginas, entre otras características.
Existen multitud de servicios en línea que permiten hacer ediciones en este tipo de documentos, pero tenemos que ser conscientes de que podemos estar enviando información privada a servidores que no controlamos, con el riesgo de que nos roben información sensible.
Vamos a ver algunas de estas aplicaciones de software libre que permiten hacer ediciones directamente desde nuestro ordenador, sin necesidad de enviar datos a servidores externos.
LibreOffice Draw
Si necesitamos hacer una edición básica, podemos emplear esta herramienta de la suite ofimática de LibreOffice (LibreOffice Draw).
PDFtk
PDFtk es una herramienta sencilla para hacer tareas cotidianas con documentos PDF. Viene en tres variantes: PDFtk Free, PDFtk Pro y la herramienta en línea de comandos PDFtk Server.
PDFtk Free es una herramienta gráfica para fusionar y dividir rápidamente documentos y páginas. Es de uso gratuito por el tiempo que desee.
PDF Arranger es una pequeña aplicación de python-gtk, que ayuda al usuario a fusionar o dividir documentos PDF y a rotar, recortar y reorganizar sus páginas usando una interfaz gráfica interactiva e intuitiva. Es un frontend para pikepdf.
PDF Arranger es una bifurcación del PDF-Shuffler de Konstantinos Poulios.
PDFSam Basic es una aplicación de escritorio gratuita y de código abierto para dividir, fusionar, extraer páginas, rotar y mezclar archivos PDF. Tus archivos permanecen privados en tu ordenador, sin necesidad de enviarlos a un servicio de terceros. Gratuito y de código abierto.
Editor de PDF de código abierto basado en el framework Qt. Con una robusta biblioteca C++, aplicaciones intuitivas para visualización/edición de PDF y una práctica herramienta de línea de comandos, PDF4QT simplifica tus interacciones con el PDF, diseñado tanto para Windows como para Linux.
Los desarrolladores tienen acceso a una robusta biblioteca C++ y a una práctica herramienta de línea de comandos. Alojado en Github y opera bajo la licencia LGPLv3.
PDFedit es un editor libre y de código abierto y una biblioteca para manipular documentos PDF, lanzado bajo los términos de la versión 2 de la GNU GPL. Incluye una biblioteca de manipulación de PDF basada en xpdf, una interfaz gráfica de usuario (GUI), conjunto de herramientas de línea de comandos y un editor de PDF.
Biblioteca multiplataforma que funciona en sistemas Unix, Windows32/64 y también en Windows CE y otros. Puedes utilizarlo para leer, cambiar y extraer información de un archivo PDF. Está basado en la biblioteca xpdf.
Continuamos con la publicación de artículos sobre proyectos libres relacionados con la Inteligencia Artificial. En este segundo artículo haremos un repaso a los MoEs (siglas en inglés de Mezcla de Expertos).
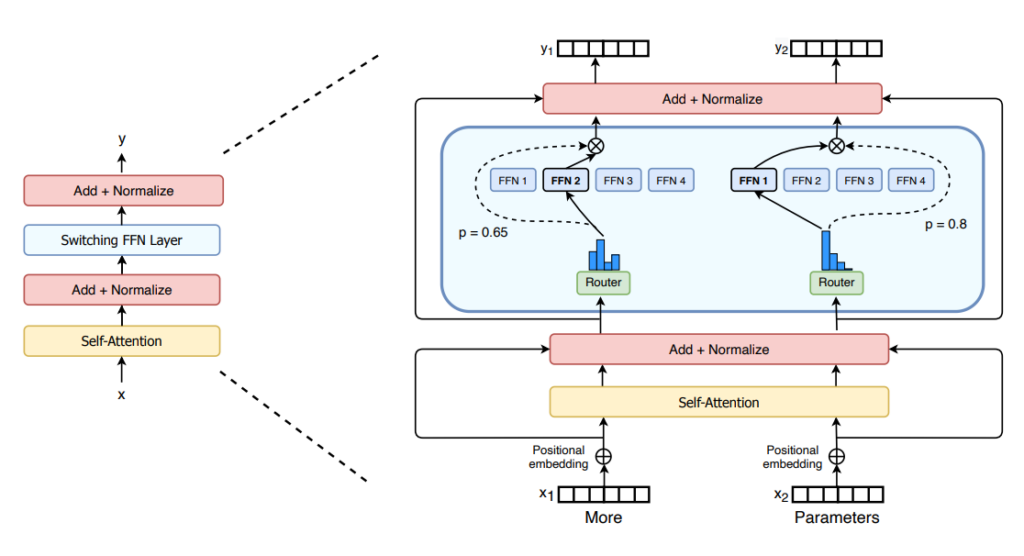
¿Qué es una Mezcla de Expertos (MoE)?
La Mezcla de Expertos en la Inteligencia Artificial es una técnica que distribuye tareas específicas entre múltiples submodelos llamados «expertos», cada uno entrenado en un dominio particular de conocimiento.
La clave de esta arquitectura radica en su capacidad para decidir dinámicamente qué experto o combinación de expertos es más adecuado para una tarea determinada, lo que permite una gestión de recursos más eficiente y una mejora en la precisión de las predicciones.
La escala de un modelo es uno de los ejes más importantes para una mejor calidad del modelo. Dado un presupuesto de computación fijo, el entrenamiento de un modelo más grande durante menos pasos es mejor que el entrenamiento de un modelo más pequeño durante más pasos.
La Mezcla de Expertos permite preentrenar modelos con mucho menos cálculo, lo que significa que puedes escalar dramáticamente el tamaño del modelo o del conjunto de datos con el mismo presupuesto de cálculo que un modelo denso. En particular, un modelo MoE debería alcanzar la misma calidad que su homólogo denso mucho más rápido durante el preentrenamiento.
Un MoE consta de dos elementos principales:
– Capas MoE, que tienen un cierto número de «expertos» (normalmente 8), donde cada experto es una red neuronal. Los expertos pueden ser redes más complejas o incluso un MoE en sí mismo.
– Una red de compuertas o enrutador, determina qué tokens se envían a qué experto. Por ejemplo, en la imagen de abajo, el token «More» se envía al segundo experto, y el token «Parameters» se envía a la primera red. Podemos enviar un token a más de un experto.
Algunas de las características de los MoEs son:
– Preentrenan mucho más rápido en comparación con los modelos densos
– Tienen una inferencia más rápida en comparación con un modelo con el mismo número de parámetros
– Se requiere alta VRAM ya que todos los expertos están cargados en memoria
– Enfrentan muchos desafíos en el ajuste fino
En resumen, la Mezcla de Expertos en la IA ofrece varias ventajas sobre otros métodos de aprendizaje automático. Es más eficiente, ya que solo necesita ejecutar un experto o una combinación de expertos para cada entrada. Además, es escalable, ya que se puede aumentar el número de expertos para mejorar el rendimiento en problemas complejos. También es versátil, ya que se puede aplicar a una amplia gama de problemas de aprendizaje automático.
Esta arquitectura ha demostrado su eficacia en aplicaciones reales y ofrece numerosas ventajas sobre otros métodos de aprendizaje automático.
Proyectos de código abierto relacionados con los modelos MoE
MoEs de acceso abierto liberados
– Switch Transformers (Google): Colección de MoEs basados en T5, desde 8 hasta 2048 expertos.
– NLLB MoE (Meta): Una variante MoE del modelo de traducción NLLB.
– OpenMoE: Un esfuerzo comunitario que ha liberado MoEs basados en Llama.
– Mixtral 8x7B (Mistral): Un MoE de alta calidad que supera a Llama 2 70B y tiene una inferencia mucho más rápida.
Mixtral 8x7b es un gran modelo de lenguaje lanzado por Mistral, que establece un nuevo estado del arte para los modelos de acceso abierto y supera a GPT-3.5 en muchos puntos de referencia.
Mixtral tiene una arquitectura similar a la de Mistral 7B, pero viene con una vuelta de tuerca: realmente son 8 modelos «expertos» en uno solo, gracias a una técnica llamada Mezcla de Expertos (MoE).
Algunas características:
– Versiones base e Instruct
– Soporta una longitud de contexto de 32k tokens
– Supera a Llama 2 70B e iguala o supera a GPT3.5 en la mayoría de los puntos de referencia
– Habla inglés, francés, alemán, español e italiano
– Buena en programación, con 40.2% en HumanEval
– Comercialmente permisiva con una licencia Apache 2.0
Empezamos coa publicación dunha serie de entrevistas e infografías que fixemos a varias persoas da comunidade de software libre, para coñecer as ferramentas que empregan no seu día a día nas súas tarefas habituais, o impacto que tivo o software libre na súa vida, consellos para empezar neste mundo e a súa relación con proxectos libres.
Elena Salgado
A primeira das entrevista fixémola a Elena Salgado, que traballa como Informática administrando o CRM dunha gran empresa:
Víctor Tilve
A segunda das entrevista fixémola a Víctor Tilve, matemático, científico no seu tempo libre, especialista en contaminación luminosa, divulgador científico e profesor de FP presencial e da Universidade a distancia:
Esperanza Martín
“Pues soy arqueóloga, topógrafo e ilustradora y me dedico a perder el tiempo excavando y haciendo cosas de esas. Últimamente estamos bastante centrados en el tema virtual y de generación de modelos tridimensionales, para la puesta en valor de diferentes yacimientos arqueológicos y colecciones.”
Sergio Fernández
“Son Sergio Fernández Alonso, morador no rural, pai de 2 e técnico de proxectos da Asociación Enxeñería Sen Fronteiras Galicia, onde fago labouras de deseño, seguimento e dinamización de proxectos que tratan de poñer a tecnoloxía ao servizo do ben común e os dereitos humanos.”
María José Ginzo
“Son Profesora Axudante Doutora no Departamento de Estatística, Análise Matemática e Optimización da Universidade de Santiago de Compostela. Doutoreime en Estatística e Investigación Operativa pola Universidade de Santiago de Compostela en maio de 2022, coa tese titulada “Técnicas Estatísticas en Geolingüística. Modelización Onomástica”. Os meus intereses de investigación inclúen a xeolingüística e a estatística espacial.”
Fco. Javier Teruelo
“Profesor de geografía e historia, antiguo Coordinador Informático, curioso profesional y practicante de la filosofía que dice que la informática es una herramienta demasiado potente para permitir que otros la gestionen por nosotros o para que no sepamos, al menos de manera aproximada, cómo funciona.”
Paola Mondaca
“Secretaria técnica da asociación Enxeñería Sen Fronteiras Galicia dende 2007.”
Evelio Sánchez
“Arquitecto pola Escola Técnica Superior de A Coruña. Compaxina a súa labor de consultor en ediliciaBIM, coa xestión do seu despacho de arquitectura, SPA Planeamento.”
Patricia Iglesias
“Técnica de educación para a transformación social da ONGD Amigas da Terra.”
Marc Romero
“Investigador predoutoral sobre medio ambiente e recursos naturais pola Facultade de Bioloxía da USC.”
Iraisy Figueroa
“Soy Iraisy Figueroa, miembro de Bricolabs. He participado activamente en la comunidad de software y hardware libre durante varios años. Trabajo con recursos de tecnologías educativas, contribuyendo a la promoción de herramientas de código abierto y colaborando con proyectos de la comunidad.”
Fernando A. Muñoz
Arqueólogo desde 1996, he realizado mas de un centenar de excavaciones, principalmente en la ciudad de León. Usuario de GNU/Linux desde 2008, empezando con Ubuntu y siempre usando Debian y derivadas. Ese mismo año, comienzo el blog de Arqueología y Software Libre para, por un lado crear una bitácora con procedimientos de uso diario, y también para dar a conocer a la comunidad arqueológica el uso de Linux y programas que se pueden utilizar día a día en nuestro trabajo.
Paula Taibo
Desde que comencé a usar software libre tengo mucho más control sobre mi ordenador y me siento más cómoda usándolo. También he aprendido mucho más sobre cómo funciona y cómo adaptarlo a mi forma de trabajo.
miércoles, 13 marzo 2024
Aplicaciones libres orientadas a empresa – Notas con QOwnNotes
En esta entrega analizaremos otra herramienta, muy útil en el trabajo, como es la toma de notas en formato Markdown. Con QOwnNotes podremos hacer esta labor de toma de notas y organizarlas de una forma sencilla y efectiva.
QOwnNotes es una aplicación libre (con licencia GPL), multiplataforma (GNU/Linux, macOS y Windows) de toma de notas que cuenta con integración en Nextcloud/ownCloud (también puede trabajar opcionalmente en conjunto con la aplicación de notas de Nextcloud y ownCloud), pudiendo sincronizar las notas entre diferentes dispositivos:
– Todas las notas se almacenan como archivos de texto plano en formato markdown en tu ordenador, pudiendo leerlas y modificarlas sin problema con diferentes herramientas de uso común, además de con la propia aplicación de QOwnNotes.
– Es una aplicación nativa, optimizada para la velocidad y que requiere poco procesador y memoria, pudiendo emplearla en dispositivos con pocos recursos de hardware.
– Altamente personalizable y programable, tienes el control sobre cómo quieres trabajar con tus notas, sin necesidad de usar formatos complejos o propietarios.
– Cuenta con una comunidad activa donde resolver tus dudas.
Otras características interesantes
– Puedes usar tus archivos de texto o Markdown existentes, sin necesidad de una importación
– QOwnNotes está escrito en C++ y está optimizado para un bajo consumo de recursos (sin necesidad de una aplicación Electron que consuma mucha CPU y memoria)
– Se pueden importar los datos directamente desde Evernote y Joplin
– Compatibilidad con la aplicación móvil y Nextcloud Textloud/ownCloud,
– Soporte para compartir notas en tu servidor ownCloud/Nextcloud
– Gestión de listas de tareas en Nextcloud/ownCloud (Nextcloud tasks o Tasks Plus/Calendar Plus) o usar otro servidor CalDAV para sincronizar tus tareas
– Puedes restaurar versiones anteriores de tus notas del servidor ownCloud/Nextcloud
– Las notas eliminadas pueden ser restauradas del servidor ownCloud/Nextcloud
– Vigilancia de cambios externos en archivos de notas
– Soporte para etiquetas de notas jerárquicas y subcarpetas de notas
– Cifrado opcional de notas, con AES-256 integrado, o puedes usar métodos de cifrado personalizados como Keybase.io (encryption-keybase.qml) o PGP (encryption-pgp.qml)
– Se pueden usar múltiples carpetas de notas
– Es posible buscar partes de palabras en las notas y los resultados de búsqueda se resaltan en las notas
– Extensión del navegador para añadir notas desde el texto seleccionado, hacer capturas de pantalla o gestionar tus marcadores
– Soporte para corrección ortográfica
– Modo portátil para llevar QOwnNotes en una memoria USB
– Soporte para scripts y un repositorio de scripts en línea donde puedes instalar scripts dentro de la aplicación
– Aplicación web para insertar fotos de tu teléfono móvil en la nota actual en QOwnNotes en tu escritorio
– Compatibilidad con temas en modo oscuro
– Los paneles se pueden colocar donde desees, incluso pueden flotar y son completamente encajables
– Modo sin distracción, modo pantalla completa y modo máquina de escribir
– Números de línea
– Las diferencias entre la nota actual y la nota cambiada externamente se muestran en un diálogo
Comenzamos con la publicación de una serie de artículos sobre proyectos libres relacionados con la Inteligencia Artificial. En este primer artículo haremos un repaso a los Modelos de Lenguaje Grande, más conocidos como LLMs.
LLMs
Los LLMs, o «Large Language Models» (Modelos de Lenguaje Grande), son sistemas de inteligencia artificial diseñados para entender, generar y trabajar con texto de manera avanzada. Estos modelos son entrenados con enormes cantidades de datos textuales para aprender patrones de lenguaje, gramática, e incluso estilo y contexto.
Su capacidad para procesar y generar lenguaje los hace herramientas poderosas para una variedad de aplicaciones, incluyendo traducción automática, generación de texto, resumen, y otros. Estos sistemas experimentaron un aumento de su popularidad desde principios del año 2023.
Los LLM libres, se distinguen por ser desarrollados y distribuidos bajo licencias que permiten a cualquiera acceder, modificar y compartir el código fuente. Esto tiene varias implicaciones importantes:
– Transparencia. Al ser abiertos, es posible revisar y entender cómo funcionan estos modelos, lo que contribuye a un mayor entendimiento de sus mecanismos y limitaciones. – Personalización. Los usuarios pueden adaptar los modelos a sus necesidades específicas, mejorando o modificando su comportamiento según requieran sus proyectos. – Comunidad y colaboración. Fomenta una comunidad de desarrolladores y usuarios que colaboran para mejorar el modelo, compartir soluciones y crear nuevas aplicaciones. – Accesibilidad. Al estar disponibles de manera gratuita, reducen las barreras de entrada para individuos y organizaciones que desean explorar o utilizar inteligencia artificial, democratizando el acceso a tecnologías avanzadas. – Ética y responsabilidad. La filosofía del software libre promueve un debate abierto sobre el uso ético de la inteligencia artificial, incluyendo la preocupación por la privacidad, el sesgo de los datos y el impacto social de los LLM.
Ejemplos de LLMs libres
– GPT-Neo y GPT-NeoX. Desarrollados por EleutherAI, estos modelos son alternativas de código abierto a las versiones comerciales de GPT (Generative Pre-trained Transformer) de OpenAI. GPT-Neo y GPT-NeoX están diseñados para ser escalables y accesibles, permitiendo a investigadores y desarrolladores trabajar con tecnología puntera en procesamiento de lenguaje natural (PLN) sin restricciones de licencia. – GPT-J. También una iniciativa de EleutherAI, GPT-J es un modelo de lenguaje de gran escala que destaca por su capacidad de generación de texto y comprensión. – Stable Diffusion. Aunque es más conocido como un modelo de generación de imágenes, Stable Diffusion también incluye capacidades de procesamiento de texto a través de CLIP, un modelo que puede entender y generar descripciones a partir de imágenes. Es un proyecto de código abierto que fomenta la innovación en varios campos de la IA. – Bloom: Desarrollado por Hugging Face y BigScience, entrenado en un conjunto de datos masivo de texto y código. – LaMDA. Desarrollado por Google AI, conocido por su capacidad para generar conversaciones fluidas y coherentes. – Megatron-Turing NLG. Desarrollado por NVIDIA y Microsoft, entrenado en un conjunto de datos de texto y código con enfoque en tareas de lenguaje natural. – WuDao 2.0. Desarrollado por la Academia de Inteligencia Artificial de Beijing (BAAI), entrenado principalmente en chino, pero también con capacidades en inglés. – BERT (Bidirectional Encoder Representations from Transformers) es un modelo desarrollado por Google que fue pionero en el uso de transformadores para entender el contexto de las palabras en un texto de forma bidireccional. Aunque el BERT original no es un LLM en el mismo sentido que los modelos GPT, su arquitectura abrió el camino para el desarrollo de muchos modelos derivados que son libres. – RoBERTa. Desarrollado por Facebook AI, RoBERTa es una optimización de BERT que mejora su rendimiento mediante el ajuste del proceso de entrenamiento y el aumento de la cantidad de datos de entrenamiento. – XLNet. XLNet es otro modelo basado en transformadores, desarrollado por Google Brain y Carnegie Mellon University, que supera a BERT en varias tareas de comprensión de texto. – OpenAI’s GPT-2. Aunque OpenAI limitó inicialmente el acceso a su modelo GPT-3 debido a preocupaciones sobre su potencial mal uso, la versión anterior, GPT-2, fue liberada completamente como código abierto. Esto permitió a investigadores y desarrolladores explorar y experimentar con las capacidades del modelo. – FairSeq. Desarrollado por Facebook AI Research, FairSeq es una biblioteca de aprendizaje profundo para secuencia a secuencia (seq2seq) que incluye implementaciones de BART, RoBERTa, y otros modelos basados en transformadores. Aunque FairSeq en sí mismo es más un marco de trabajo que un modelo específico, proporciona las herramientas necesarias para entrenar y desplegar LLMs. – TensorFlow Model Garden. Aunque TensorFlow en sí mismo es una biblioteca de aprendizaje automático de código abierto desarrollada por Google, el Model Garden ofrece un conjunto de modelos pre-entrenados e implementaciones que incluyen técnicas de última generación. – AllenNLP. Desarrollado por el Allen Institute for AI, AllenNLP es una plataforma de código abierto diseñada para la investigación en PLN. Ofrece una amplia gama de modelos pre-entrenados y herramientas para facilitar la experimentación en comprensión de lectura, inferencia textual, y más.
Estos modelos y herramientas representan solo una muestra del amplio y creciente ecosistema de inteligencia artificial libre y de código abierto. La disponibilidad de estos recursos permite a una amplia gama de usuarios, desde investigadores hasta entusiastas, explorar las fronteras de la tecnología de IA y contribuir a su desarrollo de forma colaborativa.
Plataformas de acceso a LLMs
Para acceder a estos recursos de una forma sencilla, se puede hacer a través de plataformas en línea como:
– Hugging Face. Ofrece una amplia gama de LLMs pre-entrenados, incluyendo algunos de código abierto como Bloom y LaMDA, con interfaces fáciles de usar para su implementación. – Google AI Platform. Proporciona acceso a algunos de sus LLMs más avanzados, como LaMDA y Meena. – DeepMind. Ofrece acceso a algunos de sus LLMs de investigación, como Gopher y Gato.
Problemas de los LLMs
Aunque esta tecnología tiene un gran potencial, hay que tener en cuenta que pueden presentarse diferentes problemas con su uso:
– Sesgos. Los LLMs pueden heredar sesgos presentes en los datos de entrenamiento, lo que puede generar resultados discriminatorios o injustos. Por ejemplo, si un LLM se entrena con un conjunto de datos que contiene principalmente textos escritos por hombres, es probable que genere resultados que favorezcan a los hombres. – Interpretabilidad. La complejidad de los LLMs dificulta la comprensión de cómo funcionan y por qué generan ciertos resultados. Esto puede dificultar la detección de errores o sesgos en el modelo, así como la confianza en sus decisiones. – Seguridad y ética. Es importante utilizar los LLMs de forma responsable y ética para evitar su uso con fines maliciosos. Los LLMs podrían ser utilizados para generar contenido falso, propaganda o para manipular a las personas.
Evolución de los modelos
A lo largo de los últimos años, estos modelos han tenido una rápida evolución que podemos resumir en los siguientes puntos:
– Aumento del tamaño y la complejidad. Los LLMs experimentaron un crecimiento exponencial en su tamaño, con algunos modelos actuales que albergan miles de millones de parámetros, lo que les permite procesar información con mayor precisión y generar resultados más complejos. – Mejora en la generación de texto creativo. Los LLMs ahora pueden escribir poemas, historias, guiones y incluso código con un nivel de calidad comparable al de un humano. – Desarrollo de nuevas aplicaciones. Se han implementado LLMs en diversos campos como la educación, la atención sanitaria, el servicio al cliente y el desarrollo de software, entre otros. En el ámbito educativo, por ejemplo, se utilizan LLMs para crear plataformas de aprendizaje personalizadas que se adaptan a las necesidades de cada estudiante.
En conclusión, en los últimos años han tenido lugar grandes avances en el campo de los LLMs. Estos modelos tienen el potencial de transformar la forma en que interactuamos con las computadoras y el mundo que nos rodea. No obstante, aún hay desafíos que abordar, como los sesgos, la interpretabilidad y la seguridad, para garantizar un desarrollo y uso responsable de esta tecnología.
Píldora en vídeo del artículo
Xunta de Galicia, Información mantenida y publicada en internet por Xunta de Galicia
Este sitio web utiliza cookies para que podamos brindarle la mejor experiencia de usuario posible.La información de las cookies se almacena en su navegador y realiza funciones tales como reconocerlo cuando regresa a nuestro sitio web y ayudar a nuestro equipo a comprender qué secciones del sitio web encuentra más interesantes y útiles.
Cookies estrictamente necesarias
Las cookies estrictamente necesarias deben estar habilitadas en todo momento para que podamos guardar sus preferencias para la configuración de cookies.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
Cookies de terceros
Este sitio web utiliza Google Analytics para recopilar información anónima, como la cantidad de visitantes al sitio y las páginas más populares.
Please enable Strictly Necessary Cookies first so that we can save your preferences!