
Continuamos coa publicación de artigos sobre proxectos libres relacionados coa Intelixencia Articial. Neste segundo artigo faremos un repaso aos MoEs (siglas en inglés de Mistura de Expertos).

Que é unha Mistura de Expertos (MoE)?
A Mezcla de Expertos na Intelixencia Artificial é unha técnica que distribúe tarefas específicas entre múltiples submodelos chamados “expertos”, cada un entrenado nun dominio particular de coñecemento.
A clave desta arquitectura radica na súa capacidade para decidir dinamicamente que experto ou combinación de expertos é máis adecuado para unha tarefa determinada, o que permite unha xestión de recursos máis eficiente e unha mellora na precisión das predicións.
A escala dun modelo é un dos eixos máis importantes para unha mellor calidade do modelo. Dado un presuposto de computación fixo, o adestramento dun modelo máis grande durante menos pasos é mellor que o adestramento dun modelo máis pequeno durante máis pasos.
A Mistura de Expertos permite preentrenar modelos con moito menos cálculo, o que significa que podes escalar dramaticamente o tamaño do modelo ou do conxunto de datos co mesmo presuposto de cálculo que un modelo denso. En particular, un modelo MoE debería acadar a mesma calidade que o seu homólogo denso moito máis rápido durante o preentrenamento.
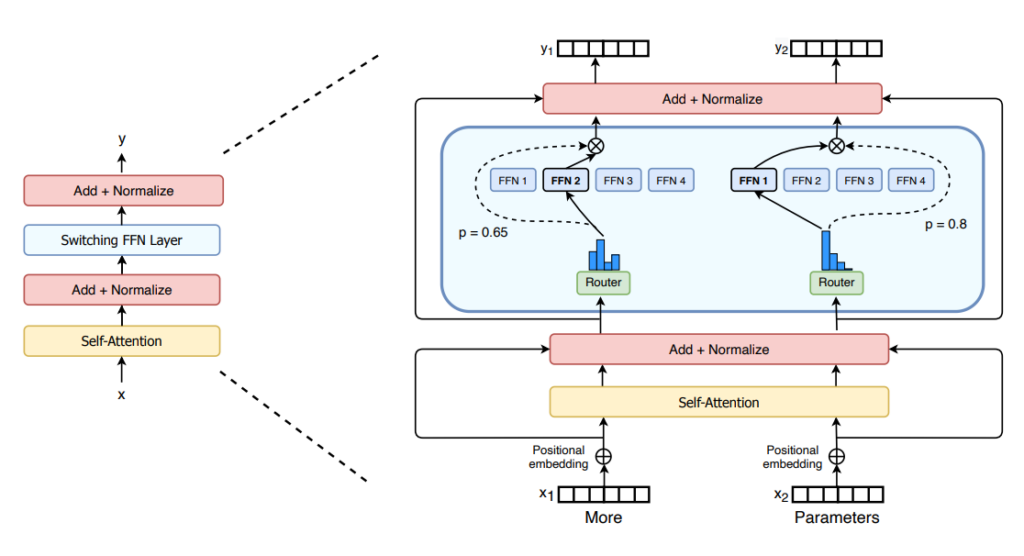
Un MoE consta de dous elementos principais:
– Capas MoE, que teñen un certo número de “expertos” (normalmente 8), onde cada experto é unha rede neural. Os expertos poden ser redes máis complexas ou incluso un MoE en si mesmo.
– Unha rede de comportas ou encamiñador, determina que tokens se envían a que experto. Por exemplo, na imaxe de abaixo, o token “More” envíase ao segundo experto, e o token “Parameters” envíase á primeira rede. Podemos enviar un token a máis dun experto.
Algunhas das características dos MoEs son:
– Preentrenan moito máis rápido en comparación cos modelos densos
– Teñen unha inferencia máis rápida en comparación cun modelo co mesmo número de parámetros
– Requírese alta VRAM xa que todos os expertos están cargados en memoria
– Enfrontan moitos desafíos no axuste fino
En resumo, a Mezcla de Expertos na IA ofrece varias vantaxes sobre outros métodos de aprendizaxe automático. É máis eficiente, xa que só precisa executar un experto ou unha combinación de expertos para cada entrada. Ademais, é escalable, xa que se pode aumentar o número de expertos para mellorar o rendemento en problemas complexos. Tamén é versátil, xa que se pode aplicar a unha ampla gama de problemas de aprendizaxe automático.
Esta arquitectura demostrou a súa eficacia en aplicacións reais e ofrece numerosas vantaxes sobre outros métodos de aprendizaxe automático.
Proxectos de código aberto relacionados cos modelos MoE
MoEs de acceso aberto liberados
– Switch Transformers (Google): Colección de MoEs baseados en T5, desde 8 até 2048 expertos.
– NLLB MoE (Meta): Unha variante MoE do modelo de tradución NLLB.
– OpenMoE: Un esforzo comunitario que liberou MoEs baseados en Llama.
– Mixtral 8x7B (Mistral): Un MoE de alta calidade que supera a Llama 2 70B e ten unha inferencia moito máis rápida.
Entrenamento dos MoE
– Megablocks: https://github.com/stanford-futuredata/megablocks
– Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
– OpenMoE: https://github.com/XueFuzhao/OpenMoE
Mixtral
Mixtral 8x7b é un gran modelo de linguaxe lanzado por Mistral, o cal establece un novo estado da arte para os modelos de acceso aberto e supera a GPT-3.5 en moitos puntos de referencia.
Mixtral ten unha arquitectura semellante á de Mistral 7B, pero vén cunha reviravolta: realmente son 8 modelos “expertos” nun só, grazas a unha técnica chamada Mestura de Expertos (MoE).
Algunhas características:
– Versións base e Instruct
– Soporta unha lonxitude de contexto de 32k tokens
– Supera a Llama 2 70B e iguala ou supera a GPT3.5 na maioría dos puntos de referencia
– Fala inglés, francés, alemán, español e italiano
– Boa en programación, con 40.2% en HumanEval
– Comercialmente permisiva cunha licenza Apache 2.0
Podes probar a conversar co modelo Mixtral Instruct en Hugging Face Chat:
https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1